
今、世界で「ChatGPT」が話題になっているのですが、2022年末にGoogleの品質評価ガイドラインの1つ「E-A-T」 に Experience の E が追加されて「E-E-A-T」に進化しました。
「ChatGPT」を利用して(ベースとして)生成されたコンテンツも出現し始めていることもあり、生成AIに負けないように今後もコンテンツを作成していく中で、「E-E-A-T」に追加されたが Experience の E (経験) がより重要になってくると思ったので、調べたり経験してきたことを備忘用にまとめてみました。
その結果は、色々な消費がモノからコトへ変わっていっているように、体験や経験をベースとした、独自性と希少性のある質の高い情報が重要になってくることを、改めて実感しました。
「E-E-A-T」とは
Google の「品質評価ガイドライン」にある、E-A-T(専門性:Expertise、権威性:Authoritativeness、信頼性:Trustworthiness)が必要なのは以前から言われていましたが、2022 年 12 月 15 日に公開されている「Google 検索セントラル ブログ」で、さらにExperience(経験)の E が追加されて「E-E-A-T」に進化しました!
そもそも E-A-T が必要になってきたのは、「YMYL」にも関係していると思われます。
YMYL(Your Money Your Life)
「Google検索品質評価ガイドライン」には、「YMYL(Your Money or Your Life)」という部分もあります。
直訳だと「あなたのお金(Your Money)、あなたの生活(Your Life)」となるのですが、『人々の健康、経済的安定、安全、社会の福祉や幸福に大きな影響を与える可能性があるジャンルを扱うページ』について、Googleは最も厳密に審査しているという内容です。
昔とは違い、公開されるようになった「Google検索品質評価ガイドライン」の「2.3 Your Money or Your Life (YMYL) Topics 」に詳細が書かれています。
原文は英語だったので、試しにChatGPTで翻訳してみました。
ウェブページは、様々なトピックについて書かれたものです。しかし、中には、その内容が人々の健康、経済的安定、安全、社会の福祉や幸福に大きな影響を与える可能性があるため、高い危険性を持つトピックがあります。これらのトピックを「Your Money or Your Life」(YMYL)と呼びます。
YMYLトピックは、以下の1つ以上を直接または間接的に影響を受ける可能性があります。
● コンテンツを直接閲覧または使用する人
● コンテンツを閲覧した人に影響を受ける他の人々
● コンテンツを閲覧した人の行動によって影響を受けるグループや社会YMYLトピックは、以下の理由により、人々の健康、経済的安定や安全、社会の福祉や幸福に直接的かつ重大な影響を与える可能性があります。
● トピックそのものが有害または危険な場合。 たとえば、自己傷害や犯罪行為、暴力的過激主義に関するトピックは、直接的に明確な害を引き起こします。
● コンテンツが正確で信頼性がある場合以外、トピックが害を引き起こす可能性があります。 たとえば、軽微な不正確さや信頼性の低い情報源からのコンテンツが、心臓発作の症状、お金の投資方法、地震の際に何をすべきか、誰が投票できるか、運転免許を取得するために必要な資格などのトピックについて、人々の健康、経済的安定、安全、または社会に影響を与える可能性があります。YMYLであるかどうかを判断するには、以下のような被害のタイプを評価します。
● YMYL健康または安全:精神的、身体的、感情的な健康、物理的な安全性またはオンラインの安全性など、あらゆる形式の安全性を損なう可能性のあるトピック。
● YMYL金融セキュリティ:人々が自分自身や家族を支援する能力を損なう可能性のあるトピック。
● YMYL社会:人々のグループ、公共の利益の問題、公共機関への信頼などに否定的な影響を与える可能性のあるトピック。
● YMYLその他:人々を傷つけたり、社会の福祉や幸福に否定的な影響を与える可能性のあるトピック。虹の科学や鉛筆の買い物など、有害でないトピックに対しても、悪意のあるコンピュータウイルスのダウンロードを含む有害なページを作成することができます。 ただし、特定のトピックがYMYLであるためには、そのトピック自体が人々の健康、金融的安定性、安全性、または社会の福祉や幸福に潜在的に影響を与える可能性がある必要があります。
多くのトピックはYMYLではなく、害を防止するために高い正確性や信頼性を必要としません。 YMYL評価はスペクトルであるため、トピックを明確なYMYL、明らかにYMYLでないもの、またはその間のものとして考えると役立ちます。明確なYMYLトピックのページは、ページ品質評価に最も厳密に審査される必要があります。
引用元:2.3 Your Money or Your Life (YMYL) Topics(General Guidelines – December 15, 2022)|ChatGPT Mar 23 Version の翻訳
(普通に内容がわかりますね。)
この「YMYL(Your Money or Your Life)」の発端になったのが、2016年12月に医療情報サイト「WELQ(ウェルク)」が、掲載内容の信頼性に関する批判が高まり閉鎖するという騒動です。

この時期にコンテンツマーケティングが流行りになっていたのですが、「WELQ(ウェルク)」では専門家ではないwebライターなどが、記事を無断転用したり、裏付けなく内容が正確でない記事を濫造したりする運営実態が明らかになりました。
ただ当時は、こういった記事でも検索結果の上位に表示されてしまっていた(SEO対策で表示ができていた)背景もあり、「WELQ(ウェルク)」だけではなく「そのような記事を上位表示させている検索エンジンにも問題がある」として、Googleへも非難が向かいました。
その結果、「YMYL」や「E-A-T(今は E-E-A-T )」が重要なコンセプトになりました。
ユーザーの検索意図
さらに記事を書いていく時には、その記事を見るであろうユーザーのことを考えて書かないと、検索結果には出てこないし、ユーザーのためにならないとGoogleさんは昔から考えているので、「ユーザーの検索意図」という形でよく表現される対応も重要になってきます。
2019年に、SEOで有名な住太陽さんがイベントで解説していた記事がweb担に出ていました。
この記事で知ったのですが、Googleの公式資料「マーケターが知るべき4つの瞬間(2015年6月)」の中に【これからのSEOでキーとなる4つの「検索インテント(意図)」】という説明がありました。

出典元:ユーザーの検索意図を狙うSEOの最新動向を住氏が解説! 売れるサイトにするための4つのポイントとは? |Web担フォーラム
この記事の中で説明されている4つのクエリですが、これを知る前に独自ドメインを色々取得していたのですが、この方向性にバッチリあっていました。(ちゃんとユーザーの意図を汲み取れていた感じがして、なんか嬉しい!)
- 知りたい(Knowクエリ):https://kosodate.shittemi.net/
- 行きたい(Goクエリ):https://kanko.ittemi.net/、https://mikoshi.ittemi.net/
- やってみたい(Doクエリ):https://toushi.yattemi.net/
- 買いたい(Buyクエリ):https://kattemi.net/
「買いたい(Buyクエリ)」以外は、それぞれサイトを作って運用しています。
「AI(人工知能)」は「意味と意図」は理解できない、という「記号接地問題」
「意図」について考えていたら、日経ビジネスで、ChatGPT(チャットGPT)を代表とした「AI(人工知能)の思考」についての面白い関連記事がちょうど公開されました。

この記事の中で、「記号接地問題(シンボルグラウンディング問題ともいう)」を最初に指摘した認知科学者スティーブン・ハルナッド氏の論文を著者が訳してくれている文章があります。
あなたは中国語を学ぼうとするが、入手可能な情報源は中国語辞書(中国語を中国語で定義した辞書)しかないとしよう。するとあなたは永遠に意味のない記号列の定義の間をさまよい続け、何かの「意味」には永遠にたどり着くことができないことになる。(*)
* Harnad, S. (1990). The symbol grounding problem. Pysica D, 42, 335-346. より著者訳。該当箇所はp338
謎解きのような感じだったのでもう少し調べてみたら、同じ論文内で「シマウマ」の例も出ていました。
“Zebra(シマウマ)” = “horse(馬)” & “stripes(ストライプ:しましま)”
シマウマを見たことがあれば、子どもでも「しましまの馬は、な〜んだ?」と聞かれれば、「シマウマ」と答えられて「黒と白のしましまのシマウマ」を想像できるのですが、「AI(人工知能)」はまだそこまで「意味と意図」は理解できていないというお話でした。
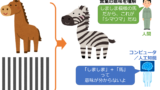

著者は『ChatGPTは、優秀な「文字列予測マシン」』と言っており、大規模言語モデル(LLM:Large Language Models)で学習した情報の中から、次にくる確率の高い文字列を予想しているだけで、「意味と意図」をちゃんと理解して返答してくれているわけではないそうです。
それにもかかわらず、ちゃんと意味を理解して会話をしているような感じで、返答をしてくれる技術もすごいのですが、それゆえに間違っていることも、さも正しいかのように返答してしまうところがあるのですね。
つまり、ChatGPT(チャットGPT)を代表とした大規模言語モデル(LLM:Large Language Models)を利用した「AI(人工知能)の思考」は、学習した情報の中から正しそうな文字列を提案することはできるものの、当然ながら学習できない(していない)新しい体験や経験を元にした返答はできないことになりますね。
これからのコンテンツは、体験や経験を元にしたものが独自性・希少性をもつことができそうですね!
0次〜3次情報について
体験や経験
を考えていくと、その「情報の質」について考えていたことがありました。
1次情報や2次情報はよく言われると思うのですが、以前どこかで0次情報という言い方も聞いたのが記憶に残っていて、改めて調べてみたのですが、各次元情報は定義されているようで定義されていなかったので、自分なりに「0次〜3次」の4つにまとめてみました。
基本的な考えになるのは、自分自身と情報との距離ですね。
0次情報
自分自身が、体験したり経験したりして得た情報ですね。
したがって、聞いたり教えてもらった情報とは違い、リアル感というかより細かいところまで感じることができます。情報との距離は自分自身の中にあるので、ほぼ「0」ですね
ただ、自分自身で経験しているので主観的な情報が多くなると思います。
1次情報
自分が主体となって、実際に体験や経験した(0次情報を持っている)人に聞いた情報ですね。
したがって0次情報を持っている本人に直接会っていたり、聞いていたりするので、ソース元がはっきりしています。それゆえに情報との距離がちょっとあるので「1」です。
直接聞いているので、信憑性や信頼性はあるのですが、0次情報と比べると主観的な情報は減るものの、客観的に見ることができる情報になります。
2次情報
ざっくり又聞きの情報ですね。
姉の友だちが言ってたんだけど、、とか、おじさんから聞いたんだけど、、というように、直接ではなく間接的(間に他の人が入っている状態)に得た情報です。
ソース元がある程度わかっているものの、第3者の意見や感情が含まれてしまっているので、1次情報と違い(間にいる人の)フィルターがかかってしまうので信憑性や信頼性にかける情報になります。
1次情報よりも少し遠くに行くので、距離が「2」です。
(実際本人に聞いてみたら、聞いていたこととぜんぜん違う形で伝わっていたことってありますよね。特に、家族親戚の話など。。)
3次情報
「信じるか信じないかは、あなた次第です!」というような情報ですね。
又聞きの又聞き・・・の情報なので、もはや本当なのかわからないし、ソース元の確認のしようがない情報になります。
一番情報からは遠くなるので、第3者的な感じで「3」次情報!
SNSや週刊誌などのメディアや噂話的な、ソース元が調べきれない上に、元々誰が言っていたのかさえもわからないような情報です。
「個人的な経験」が有益な情報になり、個人ブログが企業ブログに勝ることもある!
2023年12月に住太陽さんが下の記事を公開したのですが、「個人ブログ」がYMYL領域でもユーザーにとって有益な情報になる(=検索結果の上位に表示されることもある)ということも仰っていました。
実際に、我が家の第2子ちゃんが「ウンナ母斑」という赤いアザが首の後ろにできていて、生後10ヶ月頃からレーザー治療を始めて、2回レーザー治療(期間約10ヶ月)でほぼきれいになった経験を記事にしたら、YMYL領域の内容ですが、2019年3月に公開してから今までに17,000PV以上、検索結果からリーチしています。
医療関係のキーワードだと、ほとんど個人ブログが検索結果に表示されることはなくなっていますが、ちゃんとした経験や情報を公開すると検索結果の上位に表示されることもありました。
公開から5年、最終更新から1年ちょっと経っていますが、サーチコンソールを見てみたら過去3ヶ月でまだアクセスしてもらえているので、無価値にはなっていないようです。
医療系で病院に勝つことは難しいのですが、子どもを心配する親の気持ちから記事にしたので、誰かの役に立っているようで嬉しいですね。
引用、参照、出典の重要さ
コンテンツを作成する時に、経験を元にして書くことができれば、0次情報になるので信頼性があり独自性・希少性を出すことができますが、全て自分で経験するとなると時間と手間がかかりすぎてしまいます。
だからといって1次、2次情報が使えないわけではなく、ソース元の取得方法によって「0次情報」に近づいたような信頼性をつけることができます。
そのためには、論文やレポートの書き方と同じように「引用、参照、出典」がかなり重要になっていきます。
1次情報や2次情報であったとしても、正しい形でしっかりと「引用、参照、出典」をソース元にしてあげることで、信頼を獲得していくことができるそうです。
この点に関しても、住太陽さんが記事を書かれていました。
「引用、参照、出典」は、webの基本技術
そもそもですが、web(html)技術の元になっている「ハイパーリンク(ハイパーテキスト)」は、文書を相互にリンクさせる仕組みですが、アメリカの社会学者であり思想家でもあるテッド・ネルソンが最初につくった言葉で、その後、HyperCardなどの実用的な試みを経て、CERN(欧州原子核研究機構)という物理学研究機関に技術者として勤務していたティム・バーナーズ=リーが1989年にHTMLを考案し、Webを発明したそうです。
ティム・バーナーズ=リーは、研究や実験の情報(=論文)をどのようにシステム化するかという課題に取り組んでいる中で、論文が互いに参照し合っている関係にあることに着目して、各研究者のコンピュータに保存されている文書を相互にリンクさせるハイパーテキストの仕組みを考えたそうです。

したがって「引用、参照、出典」が重要になるのは、根本を考えれば当然の流れですね。
Google検索の成り立ちは、リンクの重要性
その後、1998年9月に設立されたGoogleの創立者ラリー ペイジとサーゲイ ブリンが、リンクを使用して個々のウェブページの重要性を判断する検索エンジンを作成します。

「引用、参照、出典」などで、文書を相互にリンクさせる仕組みが、検索エンジン「Google」の根幹になっていきました。
リンクや被リンクがどんどん重要になっていき、PageRankやリンクジュースなどの指標が作られていくことで、忘れがちになっていった感じがしますが、根本の考えは「引用、参照、出典」になると思います。
そしてAI新時代の到来か?と言われるまでになった「ChatGPT」をはじめとした「生成AI」という新しい技術が出てきた今でも、コンテンツ作成には必要な「引用、参照、出典」の重要性を住太陽さんや海外SEOブログの鈴木謙一さんなどのプロフェッショナルが教えてくれています。
話題の「ChatGPT」と進化した「E-E-A-T」から、これからのコンテンツ作成について考えてみた のまとめ
話題の「ChatGPT」と進化した「E-E-A-T」をきっかけにして、これからも続けていく「コンテンツ作成」について考えて、あれこれ考えてみました。
その結果は、色々な消費がモノからコトへ変わっていっているように、体験や経験をベースとした、独自性と希少性のある質の高い情報が重要になってくることを、改めて実感しました。
昔からGoogleさんは「有用で信頼性の高い、ユーザーを第一に考えたコンテンツの作成」を、ずっと変わらず言い続けているので、つくり手側もユーザーの事を考えた質の高いコンテンツを提供していくことが、「生成AI」との差別化になっていきますね!
色々と調べていく中で、「Google が掲げる 10 の事実」を久しぶりに見たのですが、その1つ目が一番重要かもですね。
1. ユーザーに焦点を絞れば、他のものはみな後からついてくる。
引用元:
参考にした記事
https://www.suzukikenichi.com/blog/extra-e-for-experience-added-to-e-a-t-in-latest-quality-rater-guidelines/








コメント